
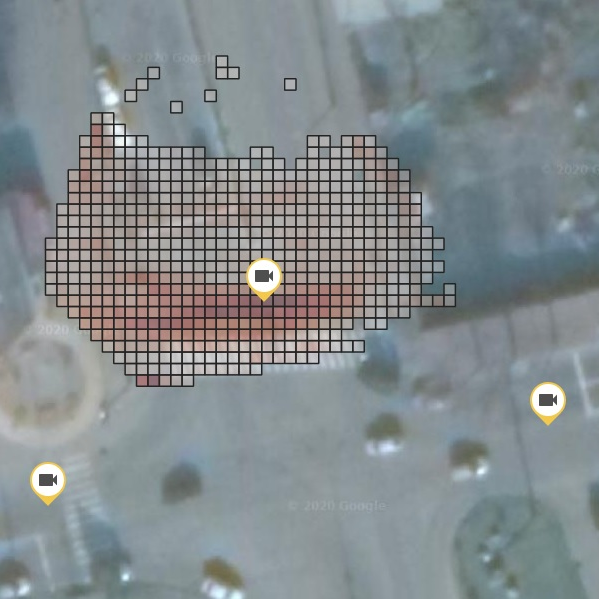
Перед нами встала задача анализа движения пешеходов и транспортных средств для автоматизированного получения различных данных на основании анализа последовательности изображений, поступающих с видеокамер в режиме реального времени или из архивных записей. С этой целью мы использовали специальное программное обеспечение, позволяющее вести мониторинг и анализ данных в автоматическом режиме. Для нашего случая была разработана система мониторинга трафика автомобилей и пешеходов на дорогах для оценки загруженности, и последующей оптимизации транспортного потока, которая была подключена к платформе cGIS.
Мы взяли данные с камер видеонаблюдения, которые отправляют видеопотоки с нескольких перекрестков города.
Каждая камера предоставляет:
Для того чтобы осуществлять анализ движения необходимо получать данные о перемещениях людей и автомобильного транспорта в области видимости камер и строить статистику на основании подсчета количества появлений того или иного класса объекта.
Но для объективной оценки загруженности дорог недостаточно просто подсчитывать появления объектов. Необходимо понимать пространственное распределение загруженности, то есть, на каких участках дорог происходят заторы с точки зрения геопространственных координат.
С наличием траекторий движений транспорта и людей появляется возможность построения тепловых карт загруженности дорог для наглядного отображения на электронной карте.
Таким образом, для поставленной задачи необходимо решить следующие подзадачи:
Параллельную обработку данных с нескольких камер было решено осуществлять с использованием Apache Kafka, позволяющей создавать очереди из кадров для каждой камеры наблюдения. Кадры с каждой камеры обрабатываются библиотекой ffmpeg, а именно:
Стоит отметить, что использование ffmpeg для раскадровки аргументировано тем фактом, что OpenCV не имеет функционала для обработки байтовых сообщений из оперативной памяти.
Для решения задачи детектирования было решено использовать модель семейства YOLO. Модели данного семейства хорошо показали себя для решения задач обнаружения объектов в реальном времени в соревнованиях VOC, ImageNet Classification Challenge и многих других.
На момент написания статьи наиболее оптимальным в данном семействе является модель YOLOv3 и ее вариации. Далее будут рассматриваться две архитектуры: YOLOv3 и Tiny YOLOv3. Вторая архитектура – это упрощенная реализация модели YOLOv3 для ускорения работы и получения большего количества кадров в секунду (FPS).
Для решения задачи отслеживания и идентификации объектов мы выбирали между алгоритмами SORT и DeepSORT.
Суть алгоритма SORT заключается в использовании фильтра Калмана для работы трекера. Основная идея фильтра Калмана состоит в том, что детектор, насколько бы он не был хорош по качеству на валидационной выборке, он может в какой то момент не обнаруживать объект из-за окклюзий, плохой видимости, или удаленности. Тем не менее, движение каждого объекта может оцениваться при помощи кинематической модели на основе предыдущих оценок. Таким образом, с начала мы получаем наиболее вероятную оценку положения объекта, а затем уточняем, когда появляются оценки от нашего детектора.
Проблемой в данном случае остается идентификация объектов, то есть, определение того, что на предыдущем кадре был именно тот же самый объект.
Обычно это достигается за счет измерения расстояния между центроидами полученных детектором прямоугольных рамок (Рисунок 1). Мы предполагаем, что между ближайшими кадрами один и тот же объект будет находится на минимальном расстоянии, но это срабатывает не во всех случаях.
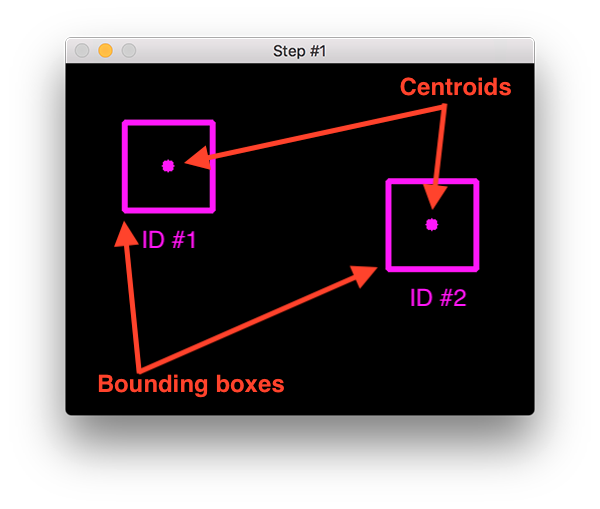
Например, два человека идут навстречу друг другу, и после их пересечения в кадре могут перепутаться идентификаторы данных объектов, что приведет к ошибкам.
Для этого алгоритм SORT модифицируется добавлением отдельной нейронной сети, которая преобразует часть изображения в предсказанной детектором рамке в вектор фиксированной длины, описывающий семантический смысл изображения со свойством расстояния, то есть, расстояния между двумя такими векторами говорят о степени схожести объектов на изображении.
Это достигается за счет обучения нейронной сети метрике расстояния, показывая на обучении похожие и не похожие друг на друга пары. На выходе получаем нейронную сеть, преобразующую изображение в вектор со свойством расстояния.
Получается алгоритм DeepSORT, который сравнивает не расстояние между центроидами прямоугольных рамок на разных кадрах, а их семантические описания. Таким образом, идентификация объекта становится более устойчивой к ошибкам типа false positive.
Проблемой для такого подхода является тот факт, что нейронная сеть, строящая семантические вектора, должна делать это для определенного класса объектов, например, для людей, легковых автомобилей, грузовиков. Поэтому, чтобы в одном кадре отслеживались как автомобили, так и люди, нам необходимо два обученных энкодера (нейронной сети, преобразующей изображение в семантический вектор) для людей и транспорта.
В решении нашей задачи мы использовали готовые весовые коэффициенты для детектора YOLOv3, распознающего 80 классов с набора данных VOC. Для энкодера по умолчанию были взяты весовые коэффициенты, предобученные на кодирование семантических векторов для людей на наборе данных Market-1501.

Так как нам необходимо еще отслеживать и автомобили, то добавилась задача обучения энкодера для объектов класса автомобилей.
Чтобы обучить энкодер преобразовывать изображения с транспортом, мы использовали набор данных VeRi, содержащий в качестве изображений пары (X — Y), где
Всего 40 тысяч изображений, где для каждого изображения есть хотя бы одна пара.

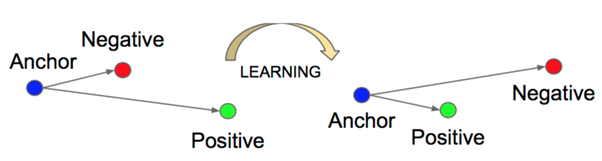
На основании имеющихся пар строятся триплеты, то есть, для пары (X – Y) (anchor – positive) подбирается изображение Z (negative), содержащее объект, не похожий на те, что содержатся в паре (X – Y). Таким образом, формируется функция потерь триплетов, чтобы обучить вектора схожих объектов находиться близко, а различные объекты – далеко друг от друга.
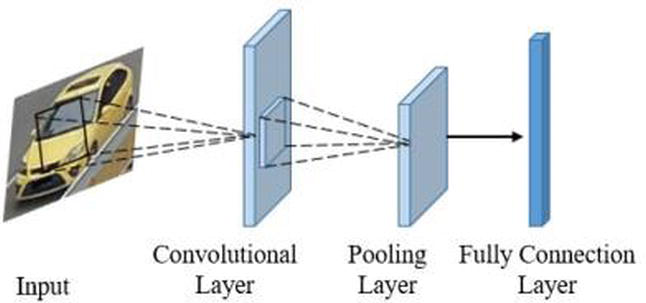
Для кодирования изображений в семантический вектор использовалась небольшая сверточная нейронная есть, состоящая из 3 сверточных (convolutional) слоев, и объединяющих (pooling) слоев между ними. На конце был установлен полносвязный (fully connected) слой размером 128.
Обучение проводилось с использованием фреймворка для машинного обучения TensorFlow на видеокарте Nvidia GeForce 1660 TI 6 GB:
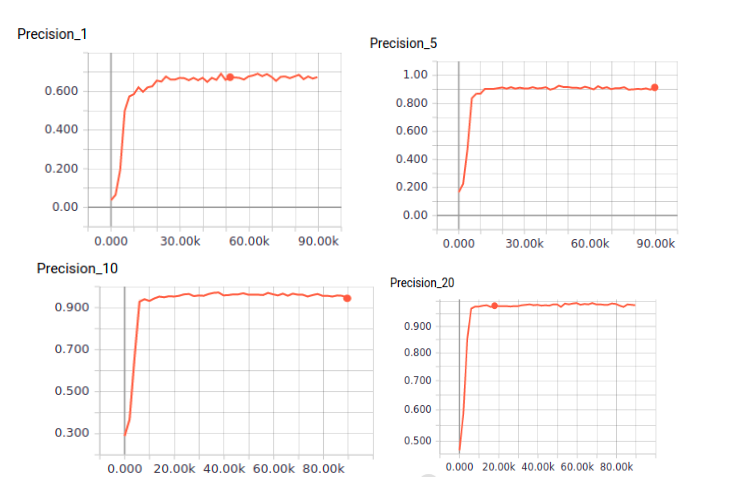
Качество оценивалось при помощи метрики качества Precision@k. Данная метрика используется для оценки качества работы поисковых систем. Если сделать запрос на определенное изображение, то метрика Precision@k выдает вероятность того, что в выборке из k изображений, полученных на запрос, появится нужный объект.
Итого мы получили следующее результаты:
| Метрика | Значение |
| Precision@1 | 0.69 |
| Precision@5 | 0.91 |
| Precision@10 | 0.94 |
| Precision@20 | 0.98 |
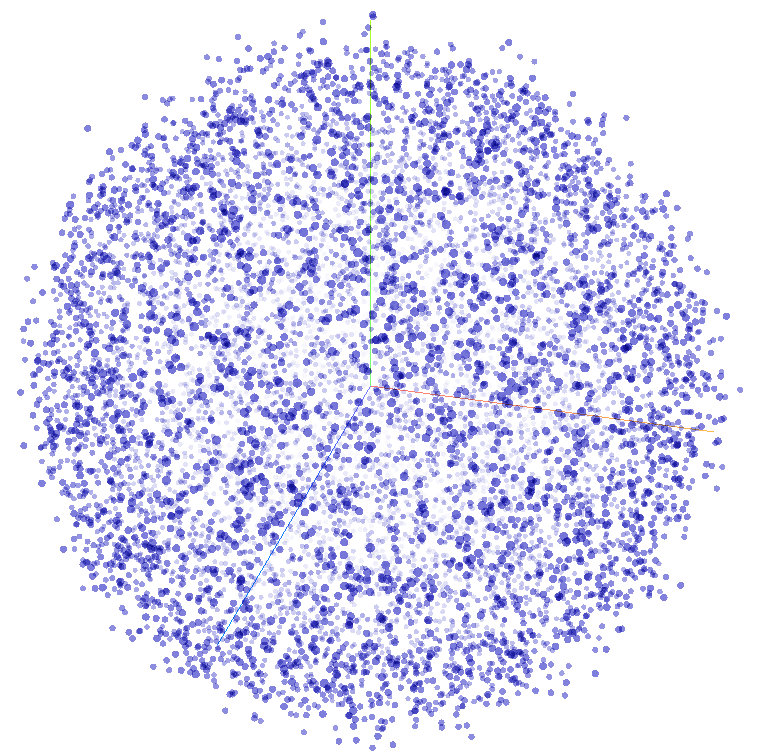
Если использовать алгоритмы уменьшения размерности векторов (например, t-SNE), посчитанных для всех 40 тысяч изображений, то можно отобразить все автомобили в семантическом 3D пространстве, где наиболее похожие друг на друга объекты расположены наиболее близко к другу (Рисунок 7).
В результате была получена легкая нейронная сеть, способная преобразовывать изображение в вектор, который имеет свойство расстояния. Чем меньше расстояние между векторами, тем более похожи друг на друга объекты на изображении.
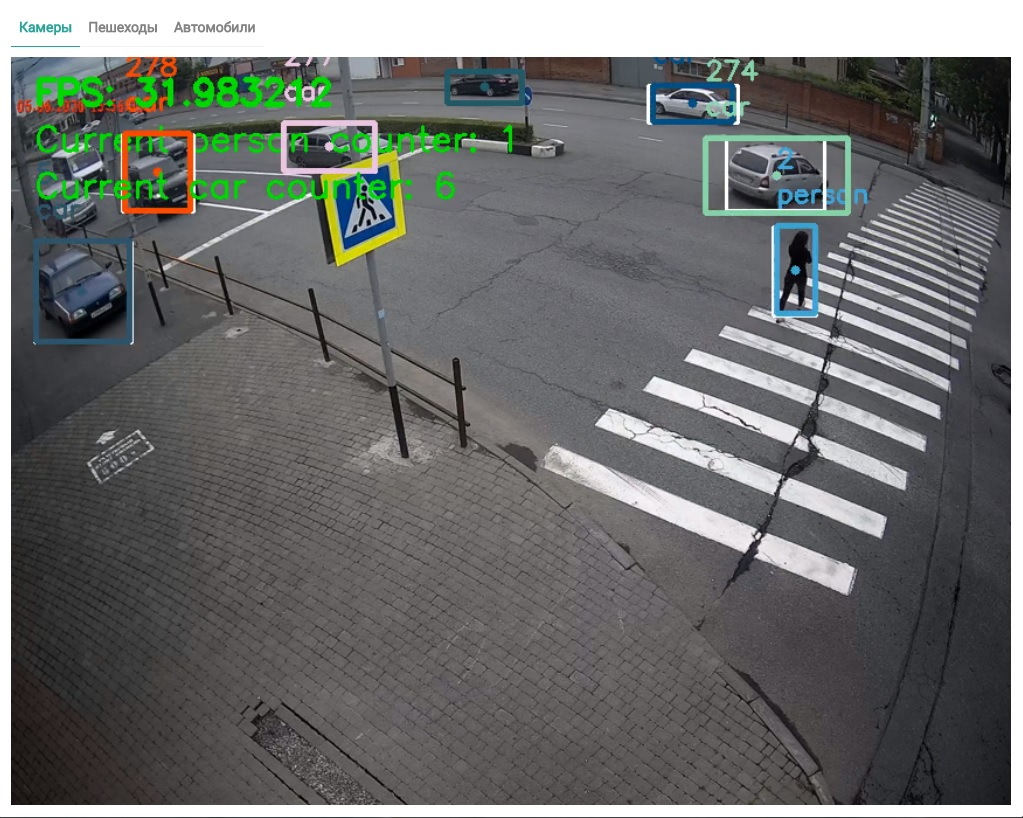
Внедрив данную нейронную сеть в алгоритм трекера, мы получили возможность детектировать трафик множества объектов разных классов, а именно, людей и транспорта (Рисунок 8).
После того, как мы получили алгоритм отслеживания объектов в видеопотоке, перед нами встала задача научиться отображать траектории объектов на карте, чтобы в дальнейшем подсчитывать интенсивность движения и степень загруженности дорог в определенный отрезок времени.
С начала мы применили перспективное преобразование. То есть, на каждой интересующей нас камере мы отметили краевые пиксели на каждом из углов изображения при том условии, что мы сможем найти объекты, привязанные к этим пикселям на карте. Это позволяет переносить объекты в плоскости камеры на плоскость поверхности Земли, сопоставляя точки на плоскости камеры с соответствующими точками Земной поверхности (Рисунок 9).

Отметив пиксели, мы нашли привязанные к ним ориентиры на карте и определили их географические координаты в формате “широта/долгота”.
Далее, средствами перспективного преобразования пиксели на камере были преобразованы в точки на карте, и полученные траектории объектов были перенесены на плоскость Земли (Рисунок 10).
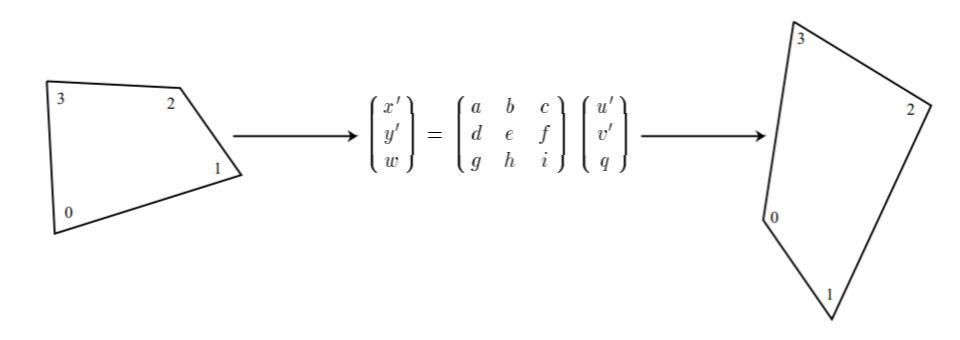
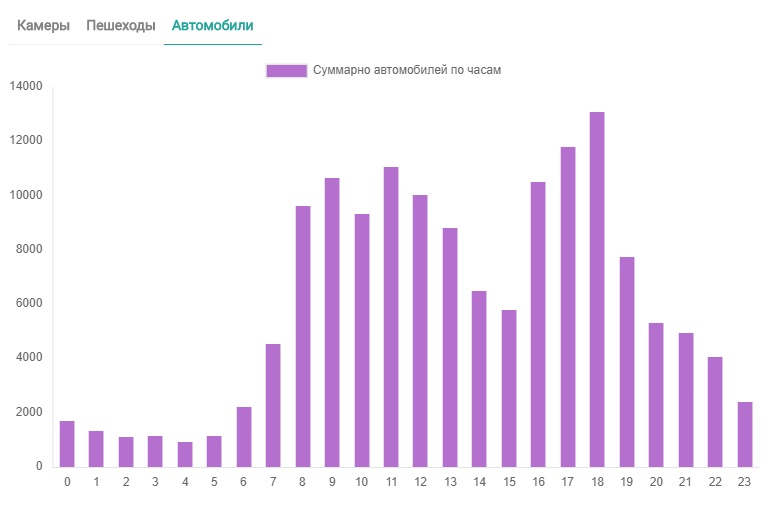
На основании полученных траекторий и частоты появления объектов были построены тепловые карты перемещения объектов и построены гистограммы появления объектов в той или иной части города, где установлены камеры.


Следующей задачей стала оптимизация алгоритмов отслеживания для использования в режиме реального времени. Так как нам необходимо обрабатывать множество камер с наименьшим количеством затрачиваемых ресурсов, то необходимо использовать все возможные инструменты, которые позволяют ускорить работу нейронных сетей.
На первой итерации, когда модель была запущена, количество кадров в секунду для одной камеры не превышало 11 FPS, то есть, модель в своем изначальном виде была слишком тяжеловесной, и не могла быть использована для работы в режиме реального времени.
Сначала мы попробовали обрабатывать только каждый 4-й кадр видеопотока, что дало линейный прирост производительности. То есть, уменьшив количество кадров в n раз мы получили n-кратный прирост производительности модели. Алгоритм стал работать с частотой кадров 40-45 FPS. Но этого все равно оказалось недостаточно, так как добавление нескольких камер таким же образом снижало скорость, что сводило данное улучшение лишь к обработке двух камер на одном сервере.
Затем мы решили изменить архитектуру детектора, но сохранить основную ее идею, применив модель Tiny YOLOv3.
Tiny YOLOv3 существенно улучшила скорость обработки видеопотока, и мы смогли обрабатывать уже 8 камер с частотой 30 FPS.
Последующее улучшения уже касались оптимизации затрат. Известно, что использовать арендованные сервера с видеокартами – крайне дорогостоящая услуга, поэтому было решено рассмотреть существующие оптимизации алгоритмов детектирования под процессоры семейства Intel.
В качестве инструмента оптимизации мы рассмотрели фреймворк компании Intel – OpenVino Toolkit. При помощи данного инструмента мы оптимизировали нашу модель под процессоры семейства Intel, и провели эксперименты с различными конфигурациями.
| № эксперимента | Количество видеопотоков | Количество виртуальных потоков (vСPU) | FPS |
| 1 | 4 | 2 | 20 |
| 2 | 4 | 4 | 35 |
| 3 | 4 | 8 | 40 |
| 4 | 8 | 2 | 18 |
| 5 | 8 | 4 | 22 |
| 6 | 8 | 8 | 25 |
| 7 | 16 | 2 | 10 |
| 8 | 16 | 4 | 12 |
| 9 | 16 | 8 | 15 |
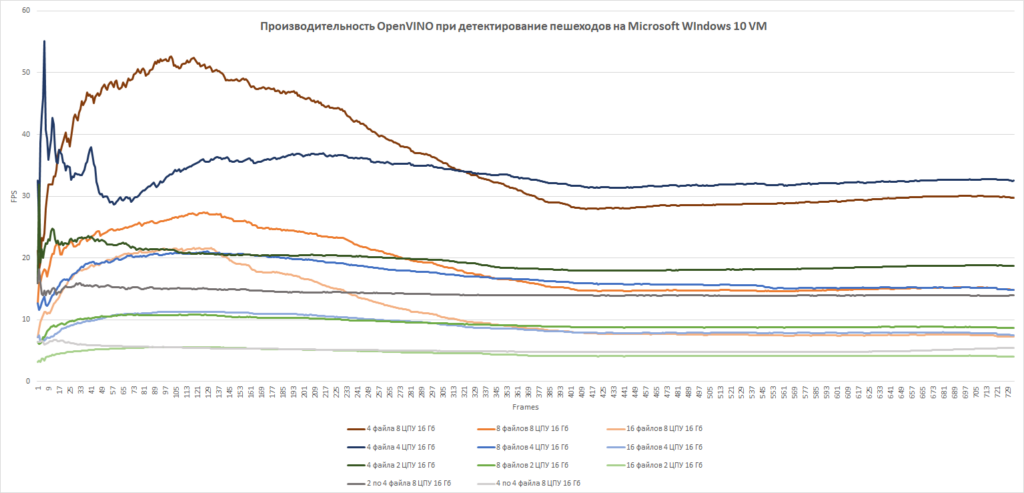
На основании проведенных экспериментов была подобрана устойчивая конфигурация для обработки видеопотоков c 8-и камер на 8 vCPU, что в дальнейшем позволило масштабировать решение с оптимальной с точки зрения бюджета серверной архитектурой.
В данной статье описан цикл исследования и разработки решения для анализа видеопотоков с камер наблюдения с получением аналитики движения транспорта и пешеходов. Разработанный стек технологий позволил нам в дальнейшем создавать другие решения в данной области с применением современных технологий в области искусственного интеллекта.